k-means Clustering
4/27/23
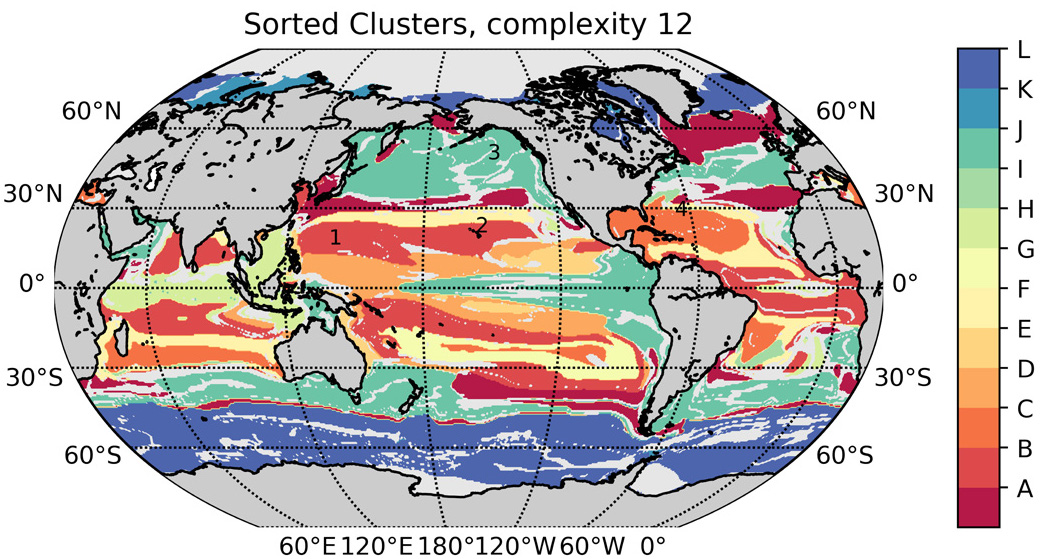
Real-life example
Marine eco-provinces
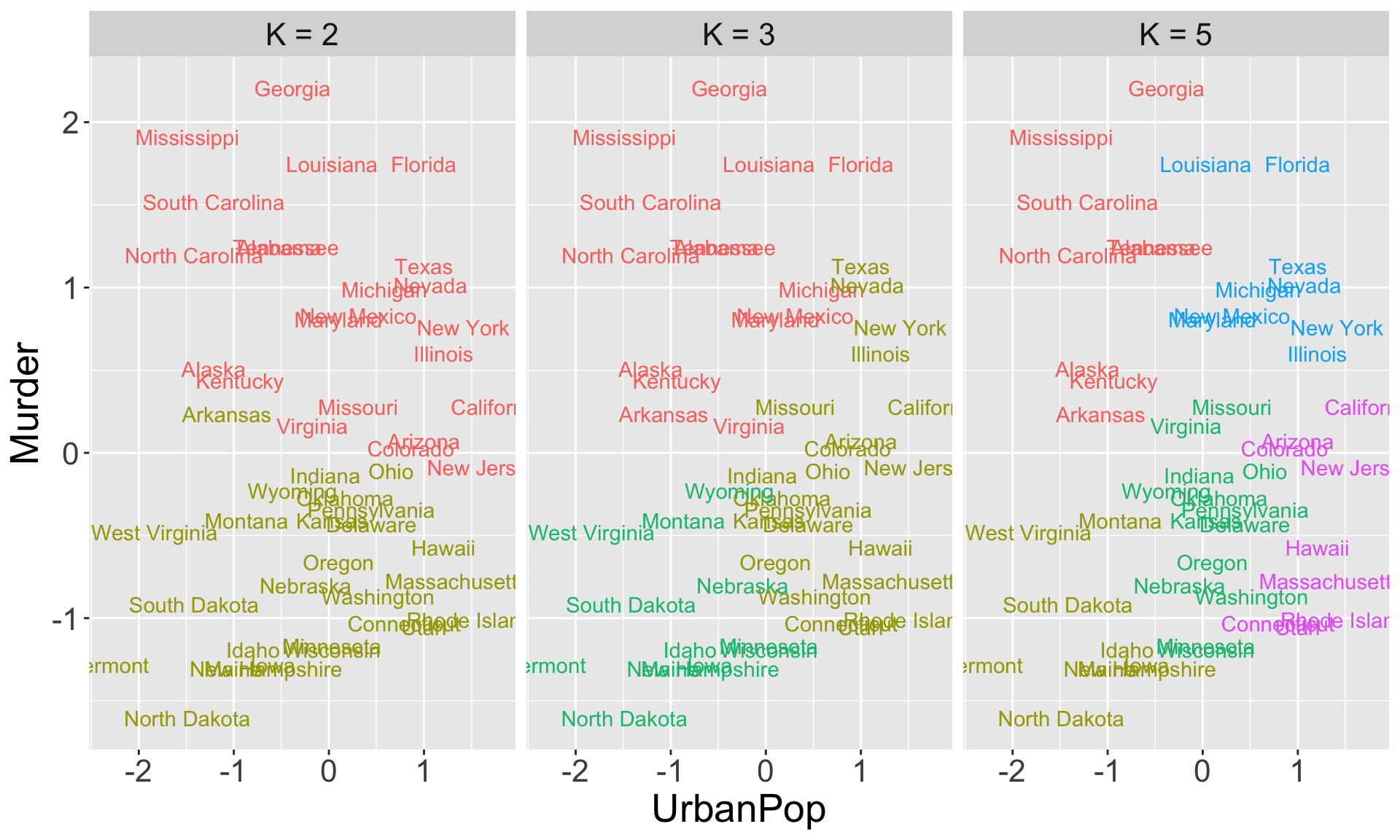
Example 1: US Arrests
Example 3: Simulated data
Generated \(n=50\) observations with two features, evenly split between two true clusters
Perform K-means clustering performed four times on the same data with \(K = 3\), each time with different random initialization.
Above each plot is the value of the objective
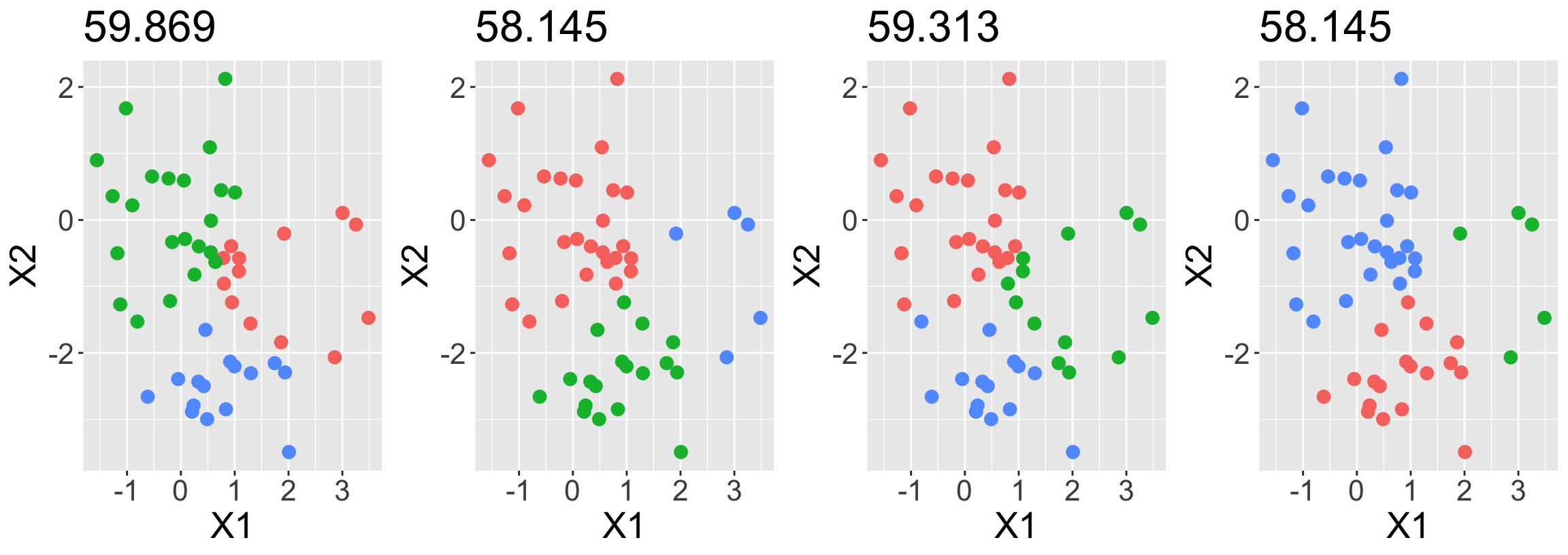
Three different local optima were obtained (three unique objective values)
One of the local optima resulted in a smaller value of the objective, and therefore provides better separation between the clusters
- Two of the initializations results in ties for best solution, with objective value of 58.145
Example 4: seeds data
Recall the
seedsdata with three varieties: Kama, Rosa, and CanadianRun \(K\)-means with \(K = 3\), using features
compactnessandarea
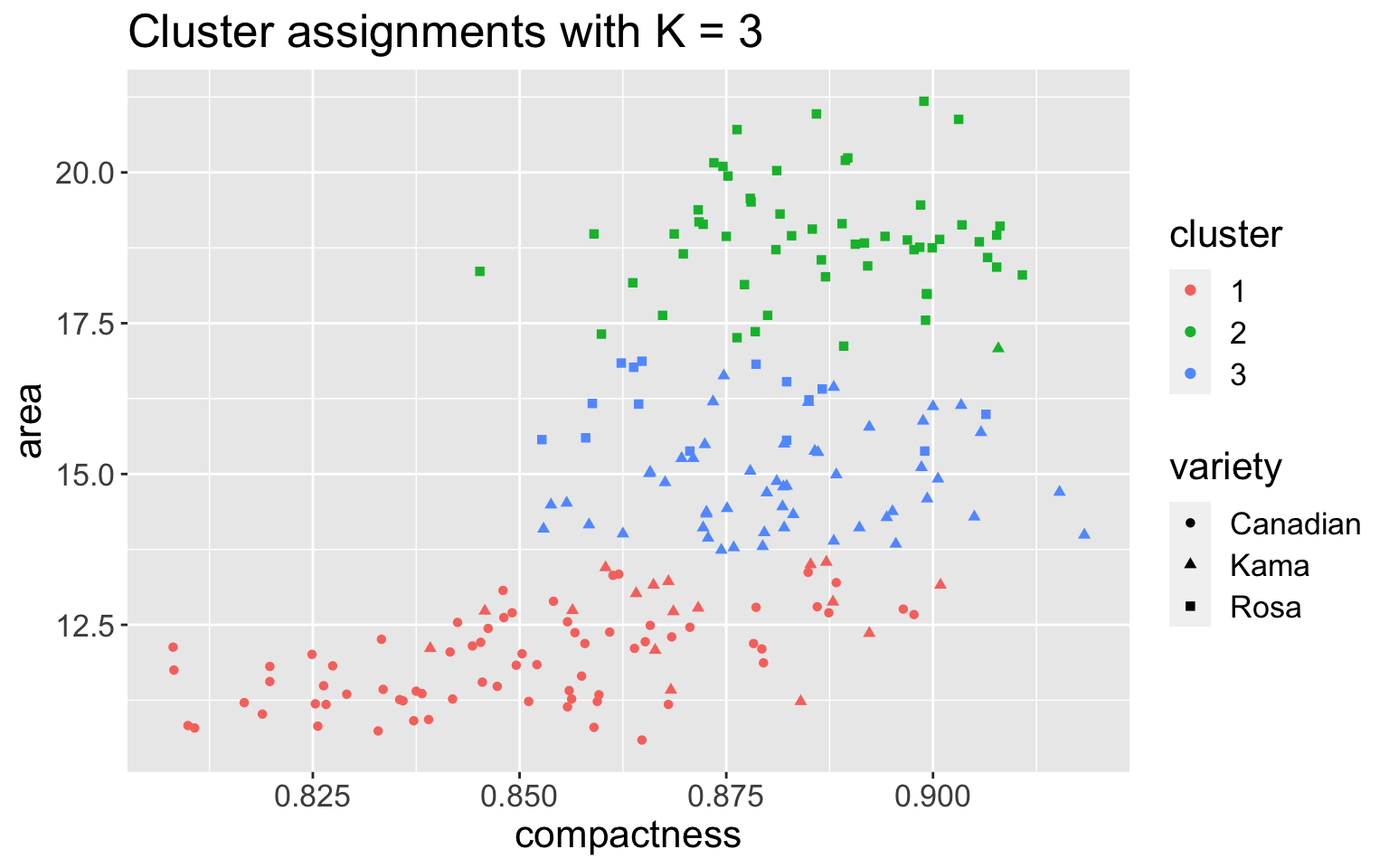
If I didn’t know there were truly three classes, how would I choose \(K\)?
Elbow method
Popular heuristic to determine the optimal value of \(K\)
Fit \(K\)-means several times with different \(K\) values, and plot the objective values against the number of clusters \(K\)
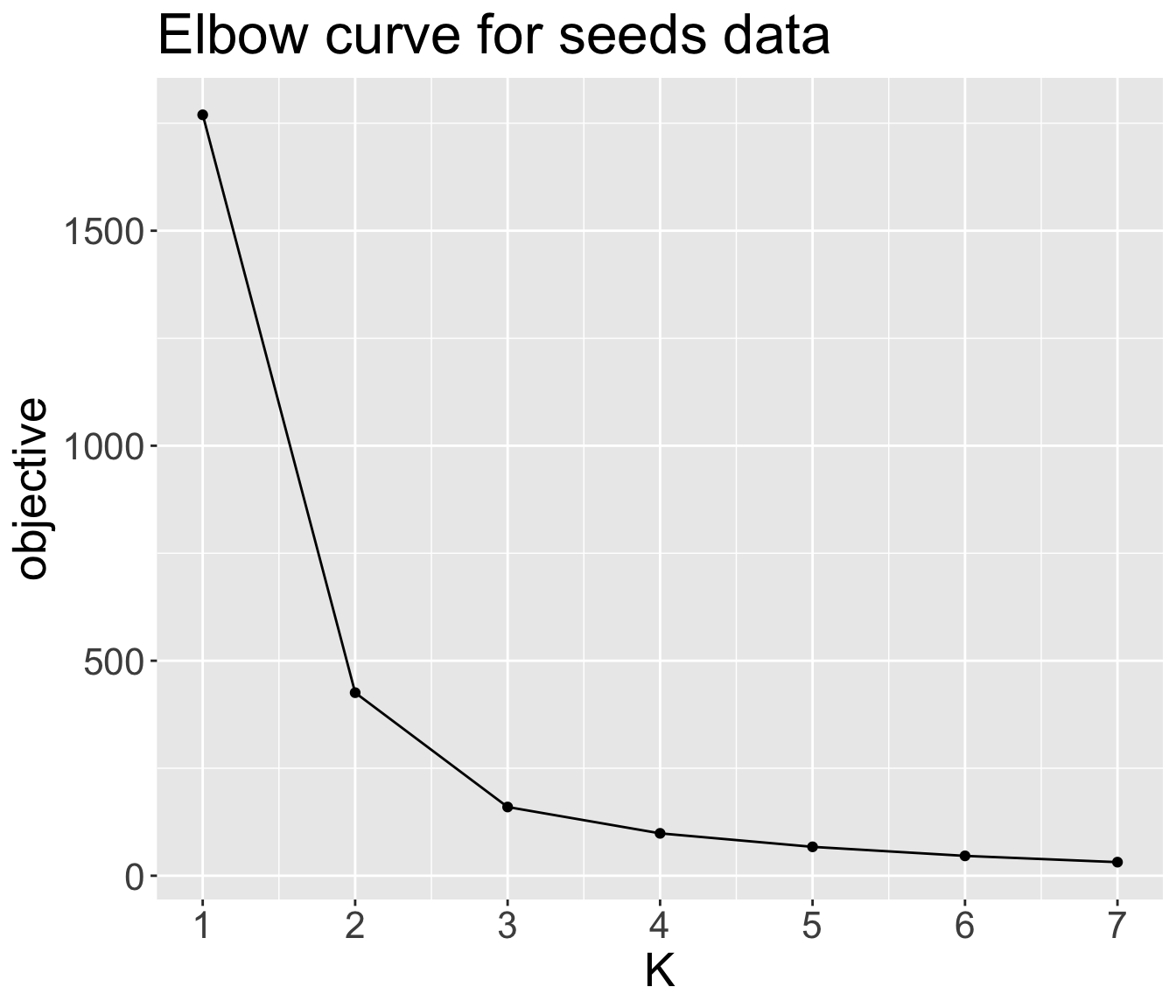
Graph will (hopefully) rapidly change at a point and thus create the elbow shape.
The \(K\) value where elbow “bends” and begins to run parallel to x-axis is taken to be optimal
What is the optimal \(K\) for the
seedsdata?
Unfortunately, it is not always obvious where the curve bends
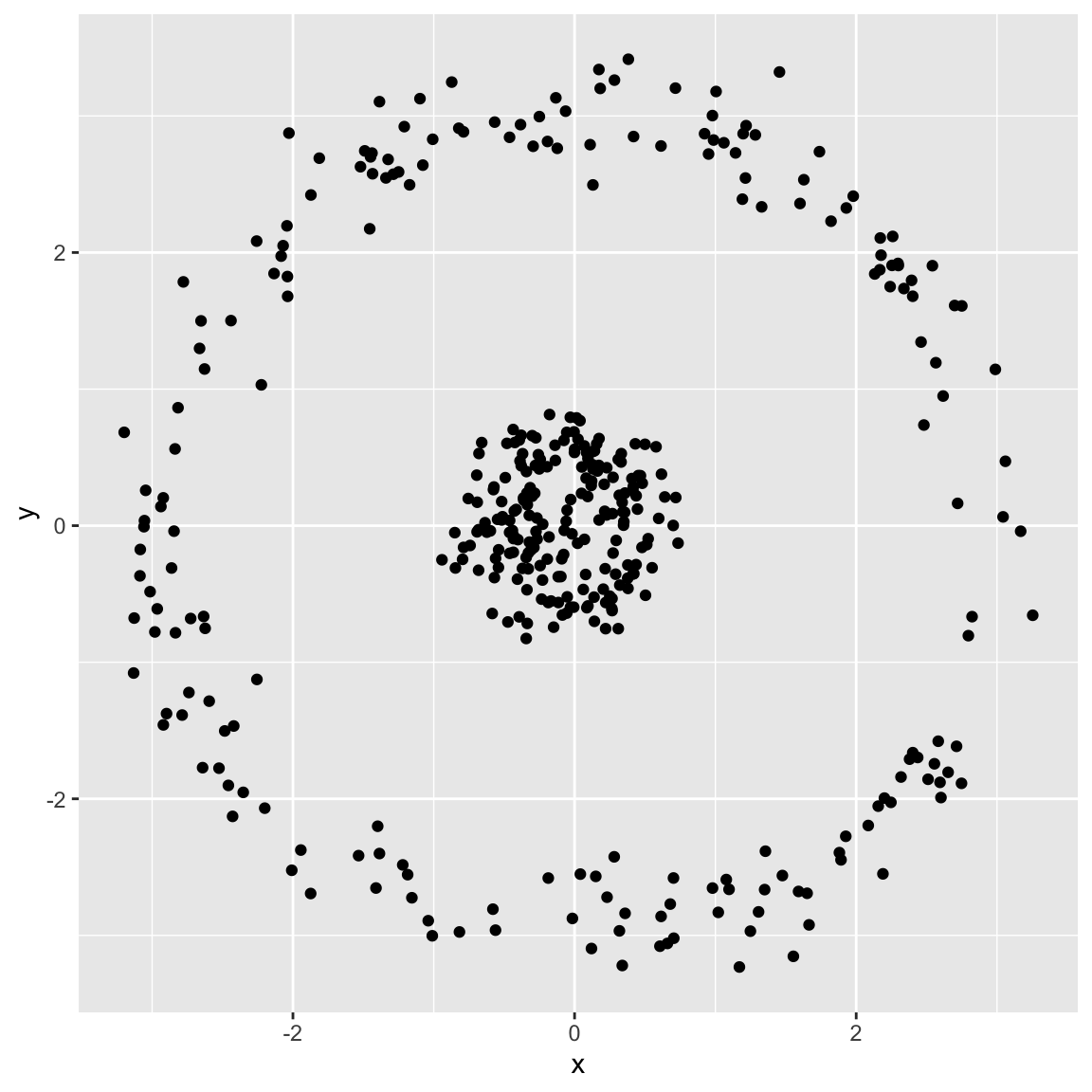
Example 5: spherical data
Generated the following data:
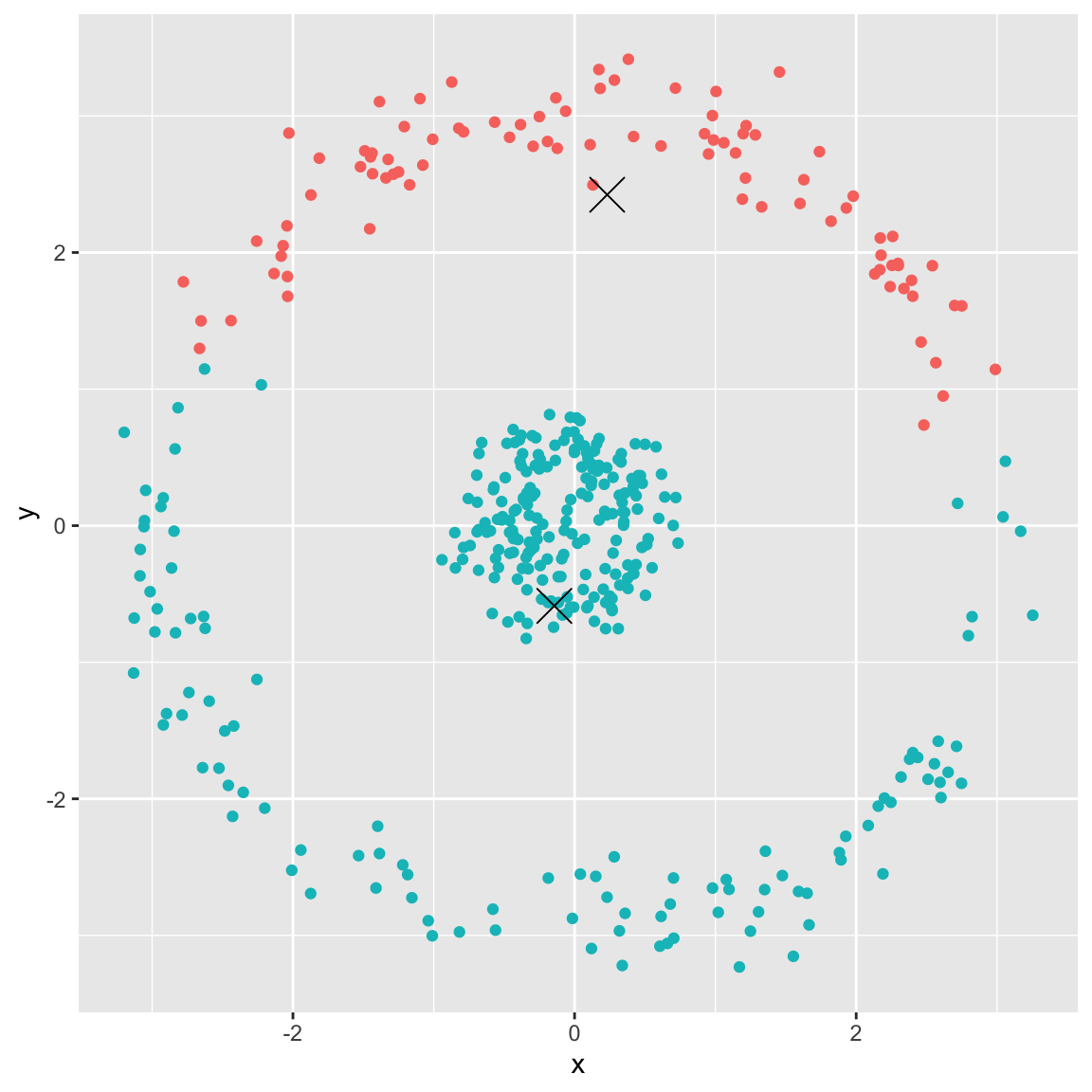
- Running \(K\)-means with \(K=2\)
Example 6: differing densities
Generated three clusters with differing densities (number of observations), \(n = 20, 100, 500\)
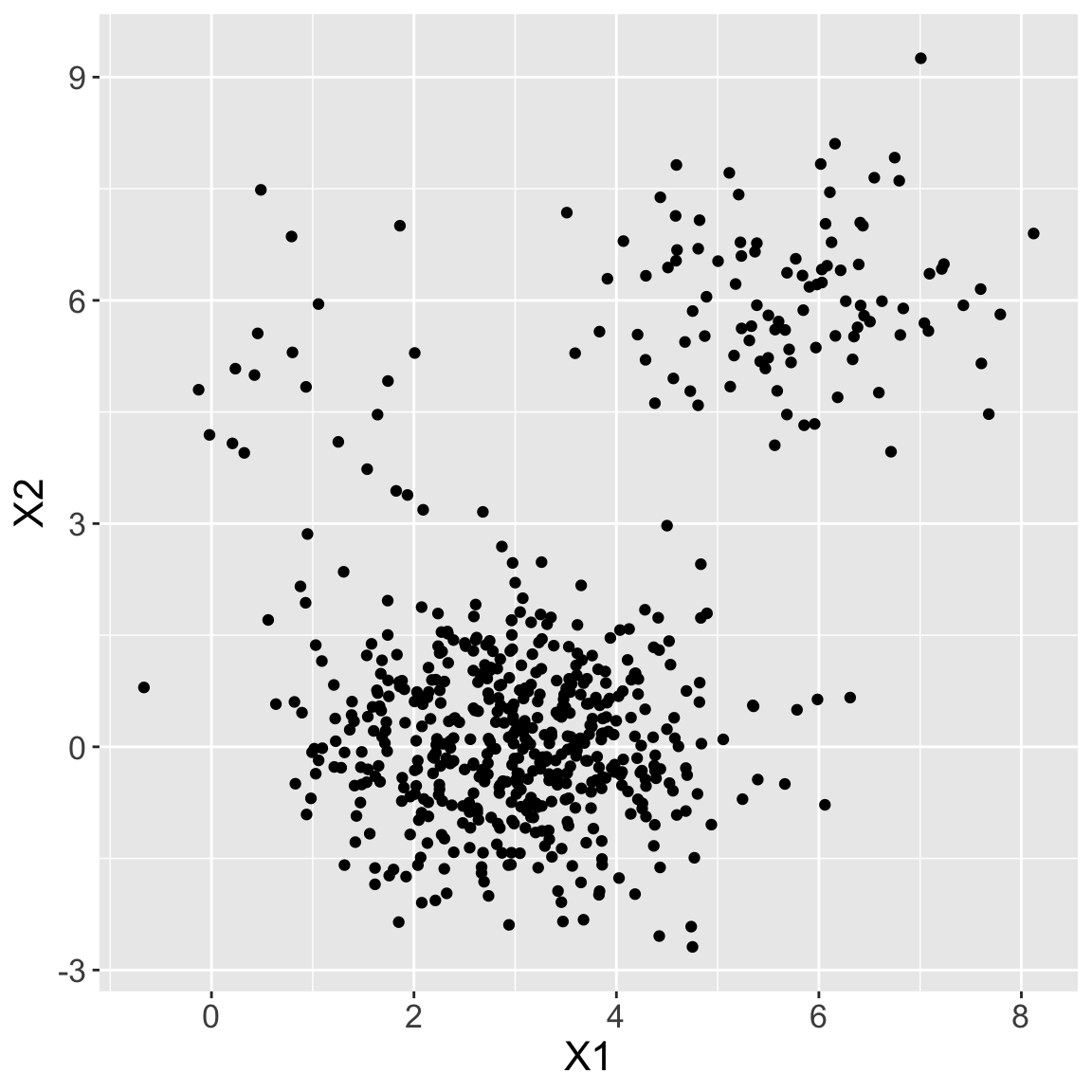
- Fit \(K\)-means with \(K = 3\). What’s happening?
