Classification Trees
Coding
4/20/23
Classification Tree
obesity_tree <- tree(class ~ ., data = train_dat,
control = tree.control(nobs = nrow(train_dat), minsize = 2))
cv_tree <- cv.tree(obesity_tree, FUN = prune.misclass)
best_size <- min(cv_tree$size[which(cv_tree$dev == min(cv_tree$dev))])
prune_obesity <- prune.misclass(obesity_tree, best = best_size)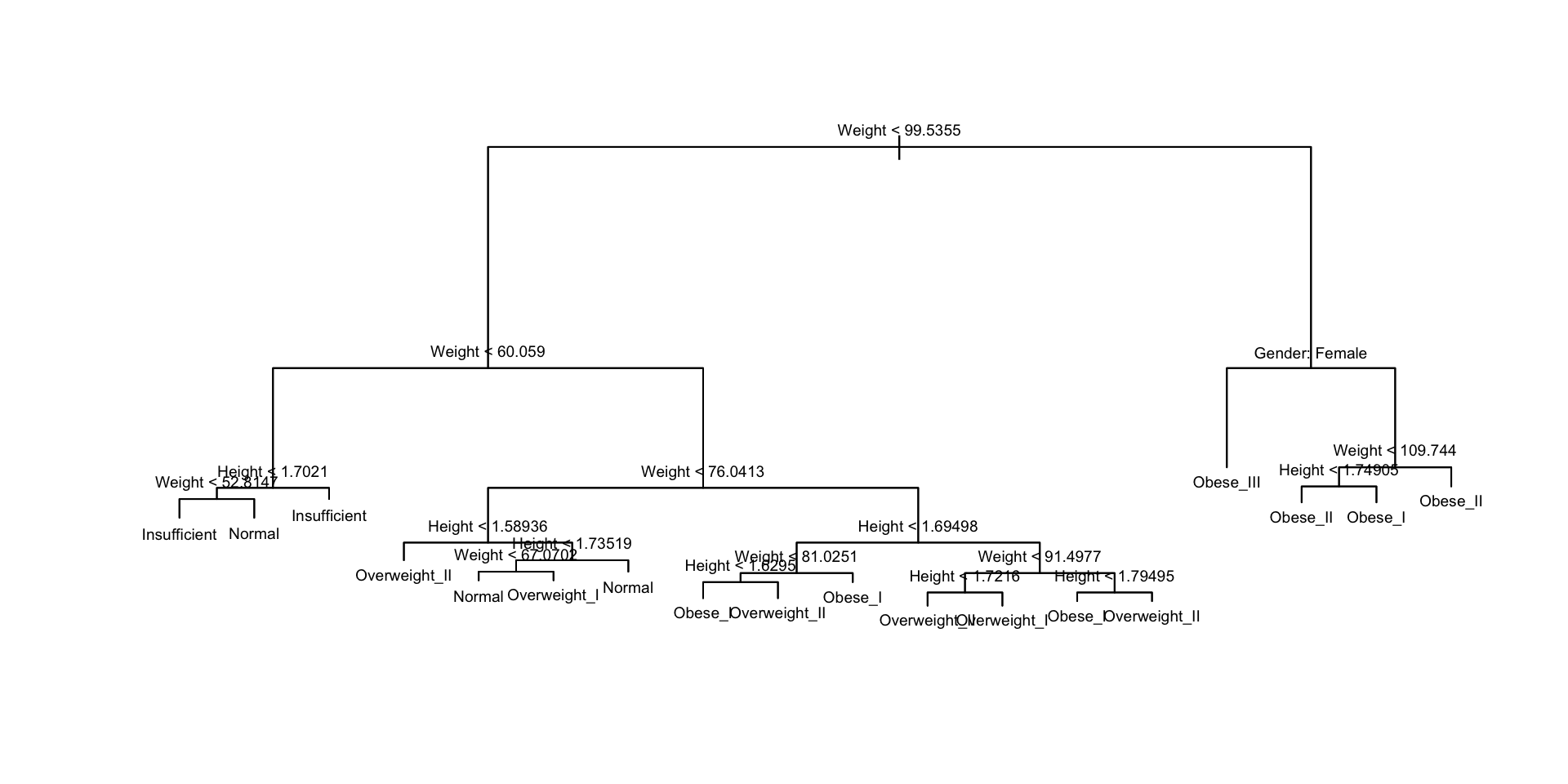
Bagged classification trees
Quickly discuss/remind ourselves: what does bagging for trees look like?
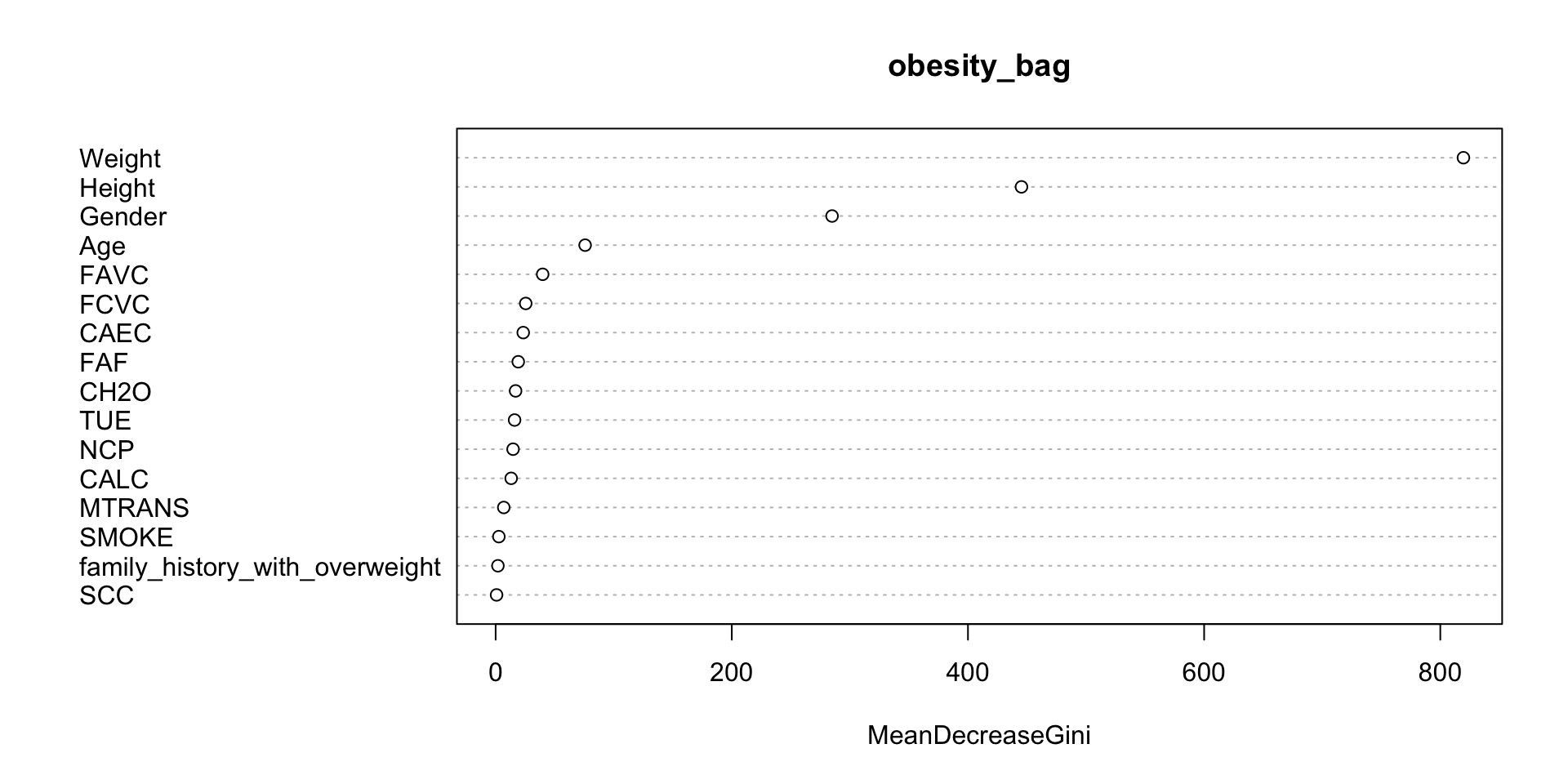
- The “importance” is defined as the total amount that the Gini index decreases by splits over a given predictor \(X_{j}\), averaged over the \(B\) trees
Random forests
For random forests, we typically set the number of predictors to consider at each split to be \(\approx \sqrt{p}\), where \(p\) is the total number of available predictors

[1] "Misclass rate: 0.05"