Model Assessment and KNN Classification
4/6/23
Model assessment in classification
In the case of binary response, it is common to create a confusion matrix, from which we can obtain the misclassification rate and other rates of interest
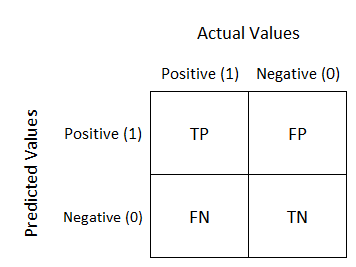
FP= “false positive”,FN= “false negative”,TP= “true positive,TN=”true negative- “Success” class is the same as “positive” is the same as “1”
Can calculate the overall error/misclassification rate: the proportion of observations that we misclassified
- Misclassification rate = \(\frac{\text{FP} + \text{FN}}{\text{TP} + \text{FP} + \text{FN} + \text{TN}} = \frac{\text{FP} + \text{FN}}{n}\)
Varying threshold
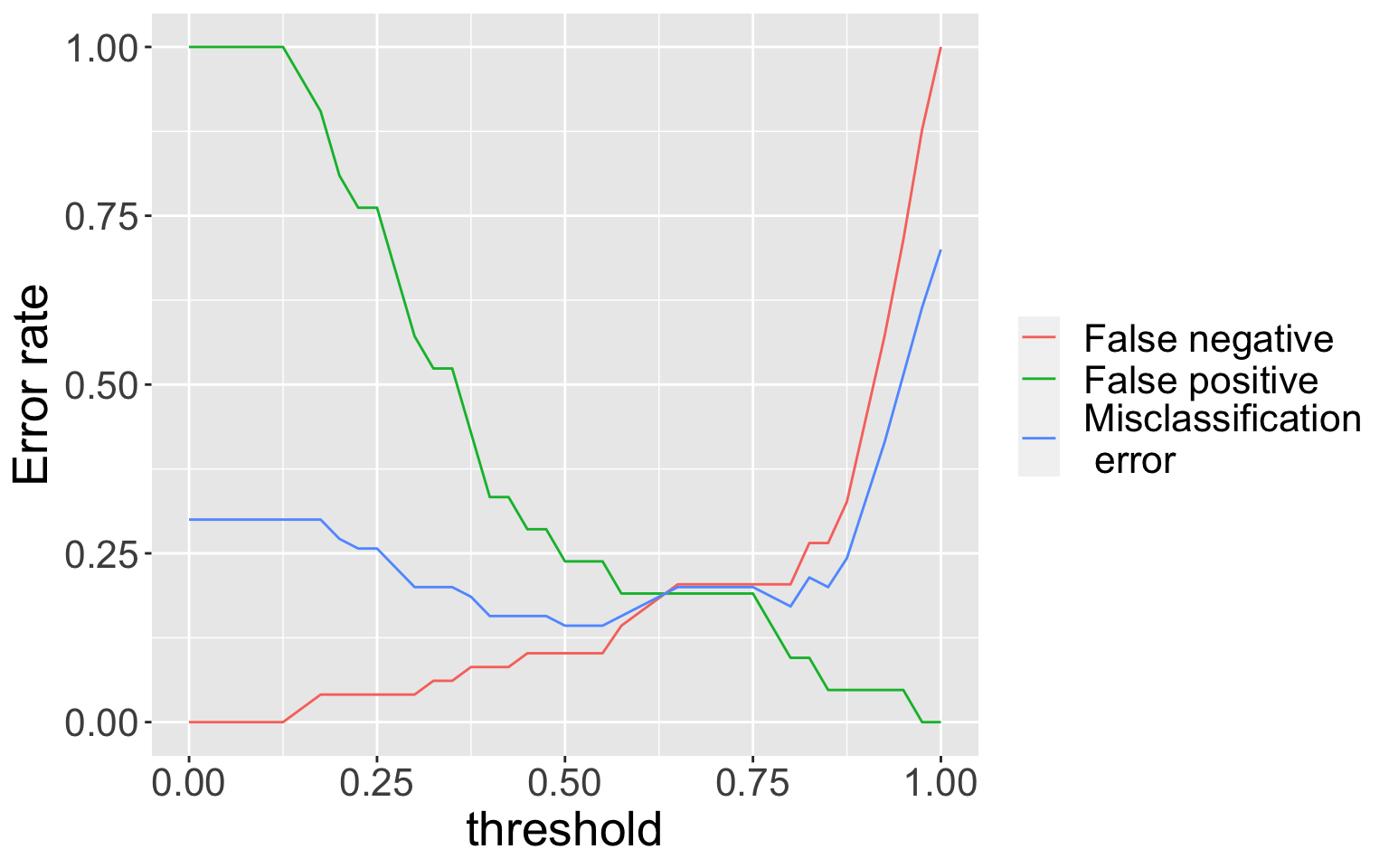
Overall error rate minimized at threshold near 0.50
How to decide a threshold rate? Is there a way to obtain a “threshold-free” version of model performance?
ROC Curve (cont.)
ROC and AUC for the training data:
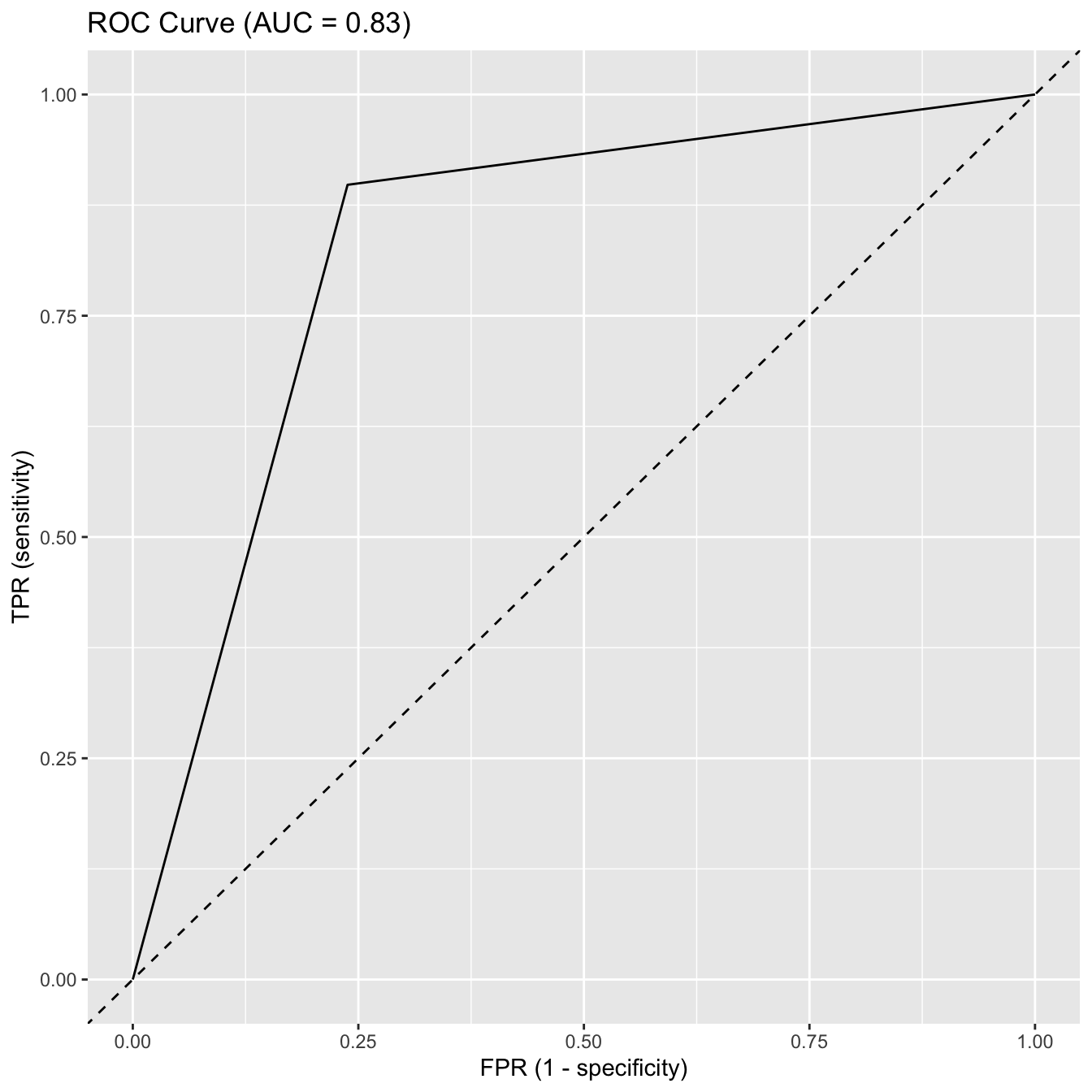
- How do you think we did?
Example: mite data
This is a similar plot to that from KNN regression slides, where now points (plotted in standardized predictor space) are colored by
presentstatus instead ofabundance.Two test points, which we’d like to classify using KNN with \(K = 3\)

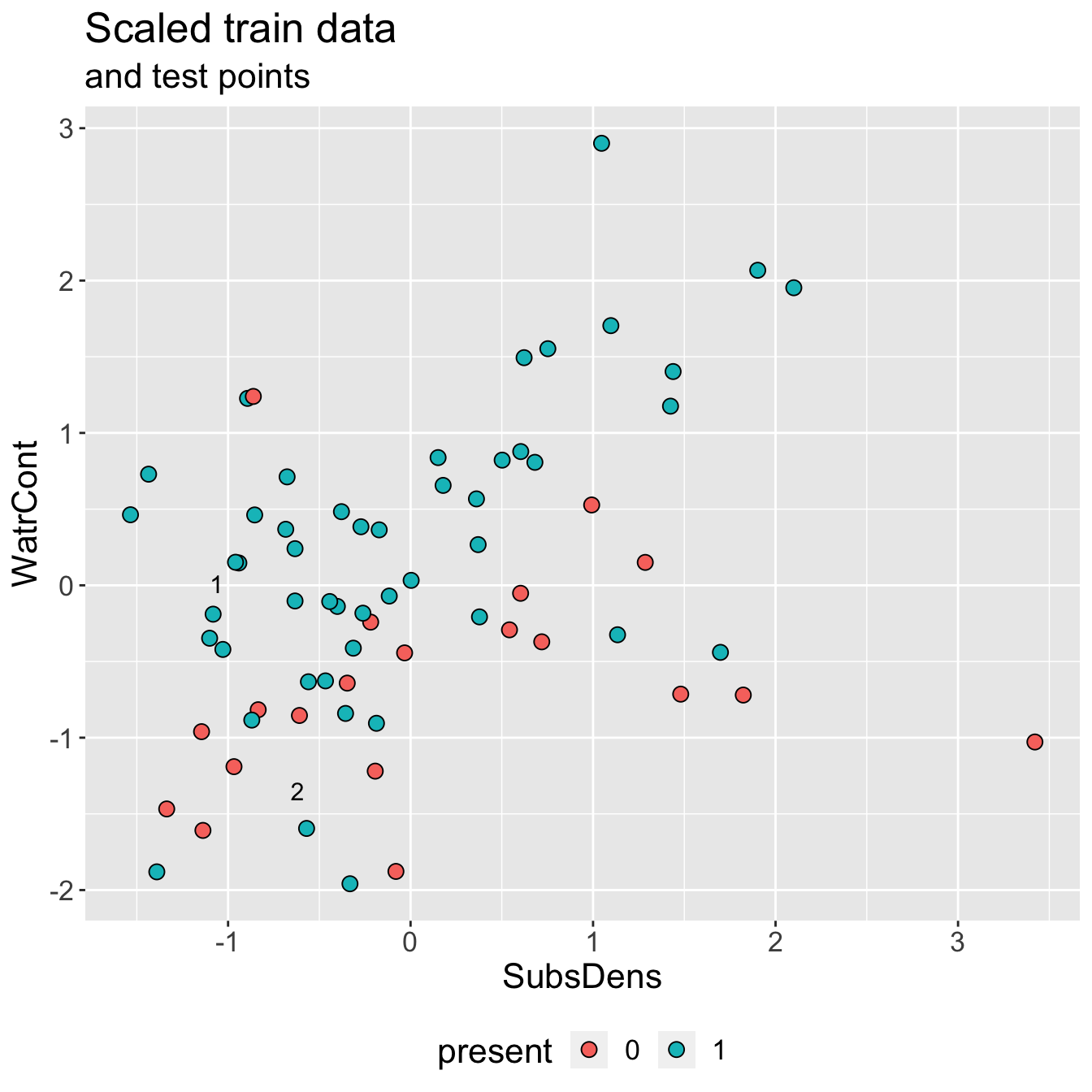
How would we classify?
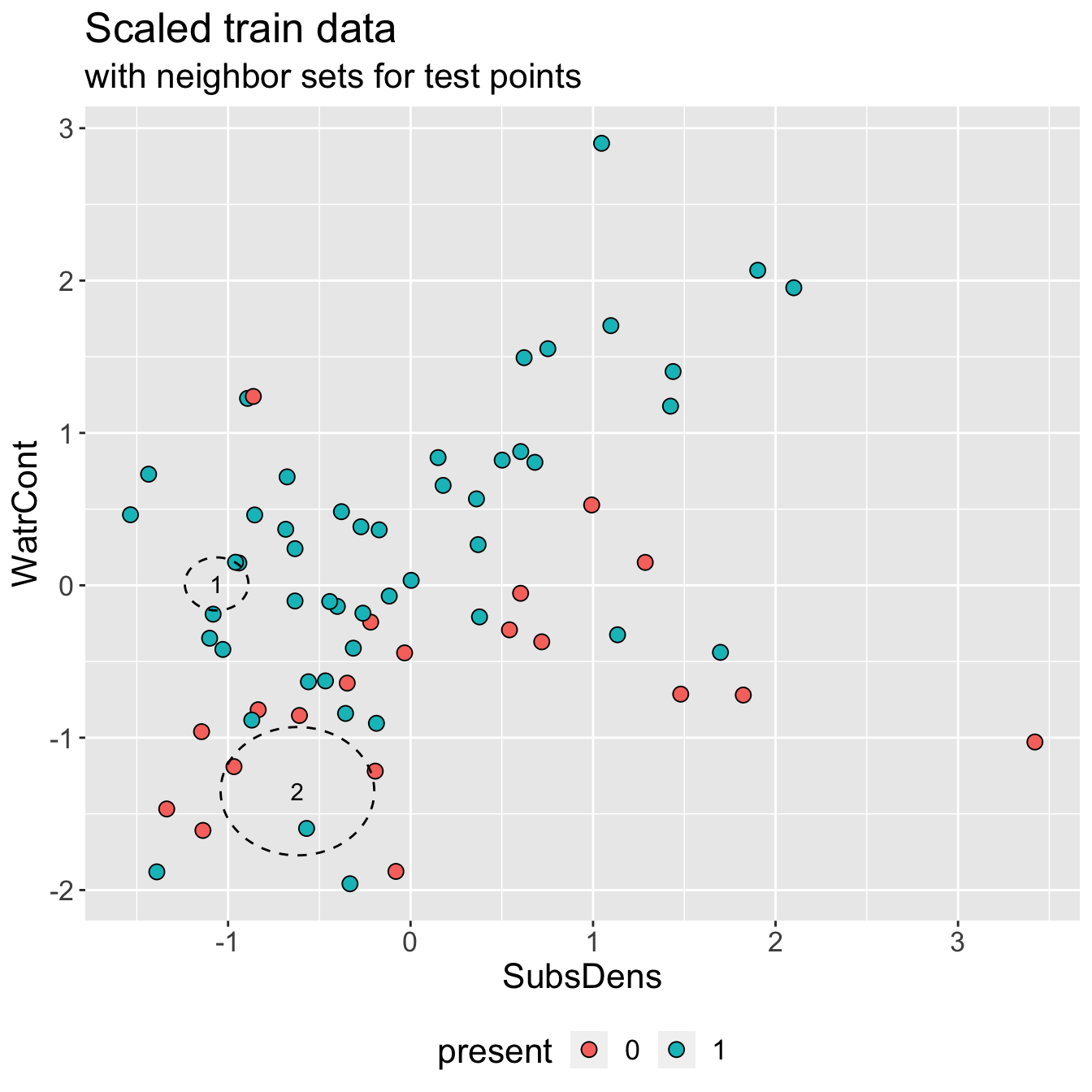
Discuss: which class labels would you predict for test points 1 and 2, and why?
- Estimated conditional class probabilities \(\hat{p}_{ij}(\mathbf{x}_{i})\) are obtained via simple “majority vote”:
- \(\hat{p}_{1, \text{present}}(\mathbf{x}_{1}) = \frac{3}{3} = 1\) and \(\hat{p}_{1, \text{absent}}(\mathbf{x}_{1}) = \frac{0}{3} = 0\)
- \(\hat{p}_{2, \text{present}}(\mathbf{x}_{2}) = \frac{1}{3}\) and \(\hat{p}_{2, \text{absent}}(\mathbf{x}_{2}) = \frac{2}{3}\)
KNN classification: different K
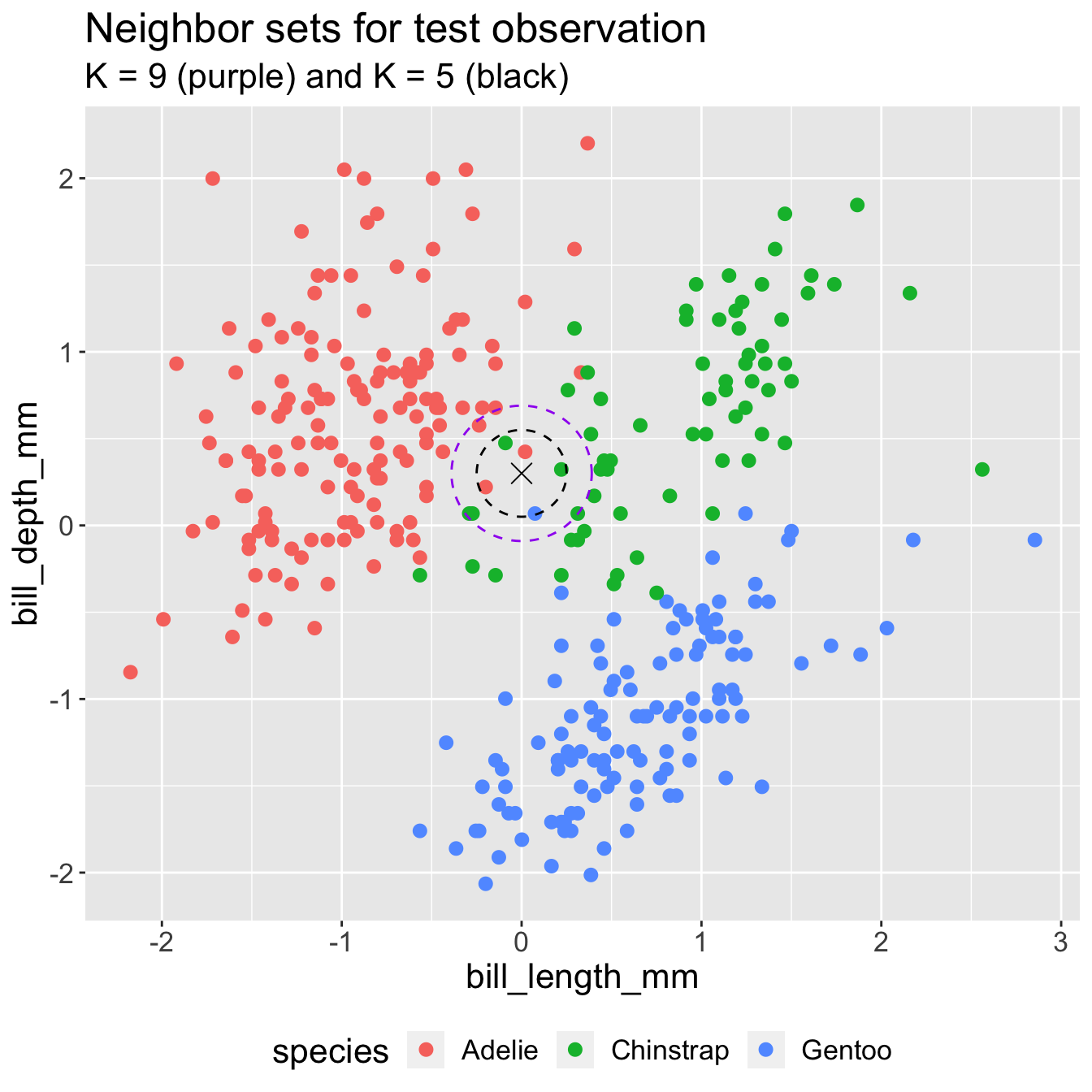
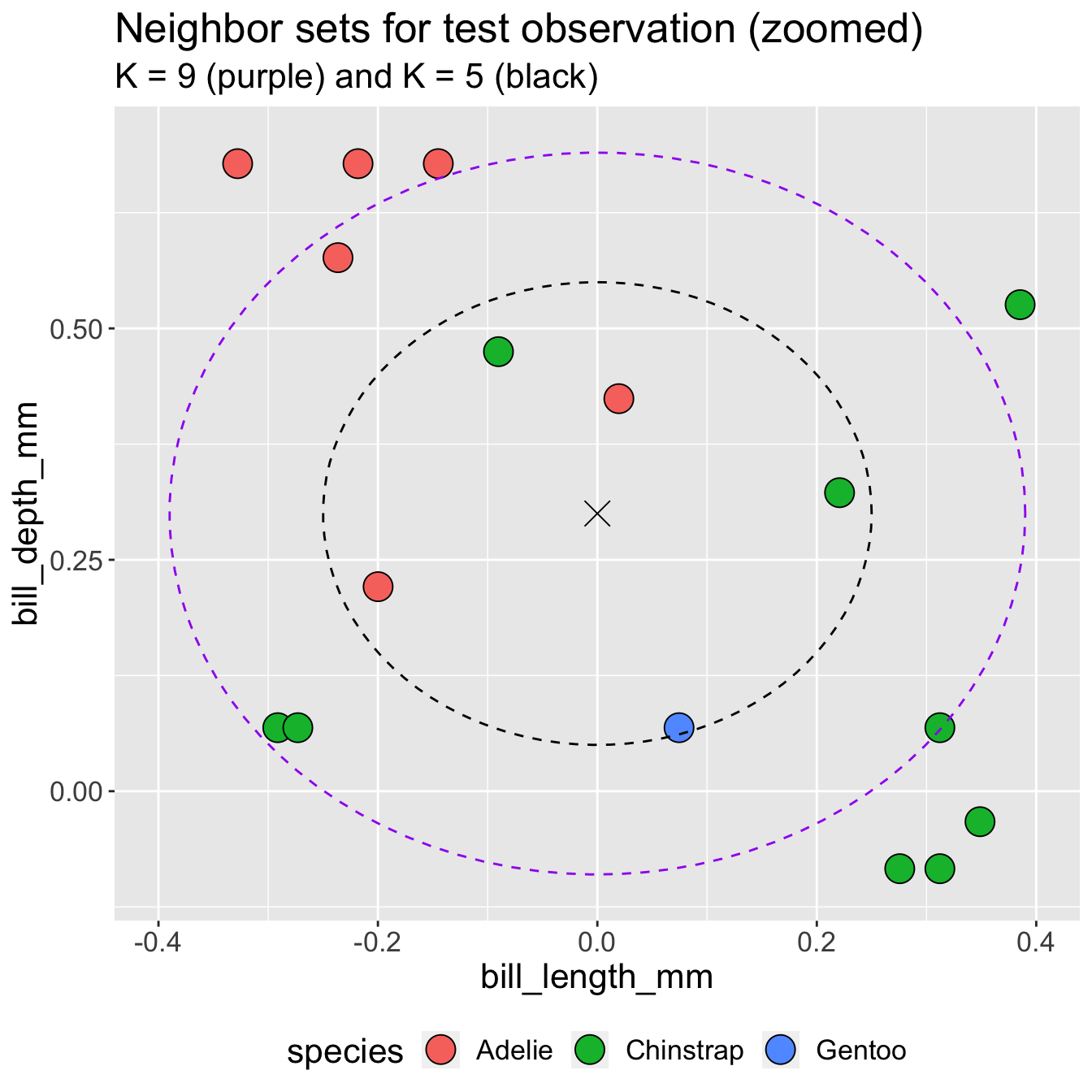
- What class would you predict for the test point when \(K = 9\)?
- What class would you predict for the test point when \(K = 5\)?