Bagging and Random Forests
3/30/23
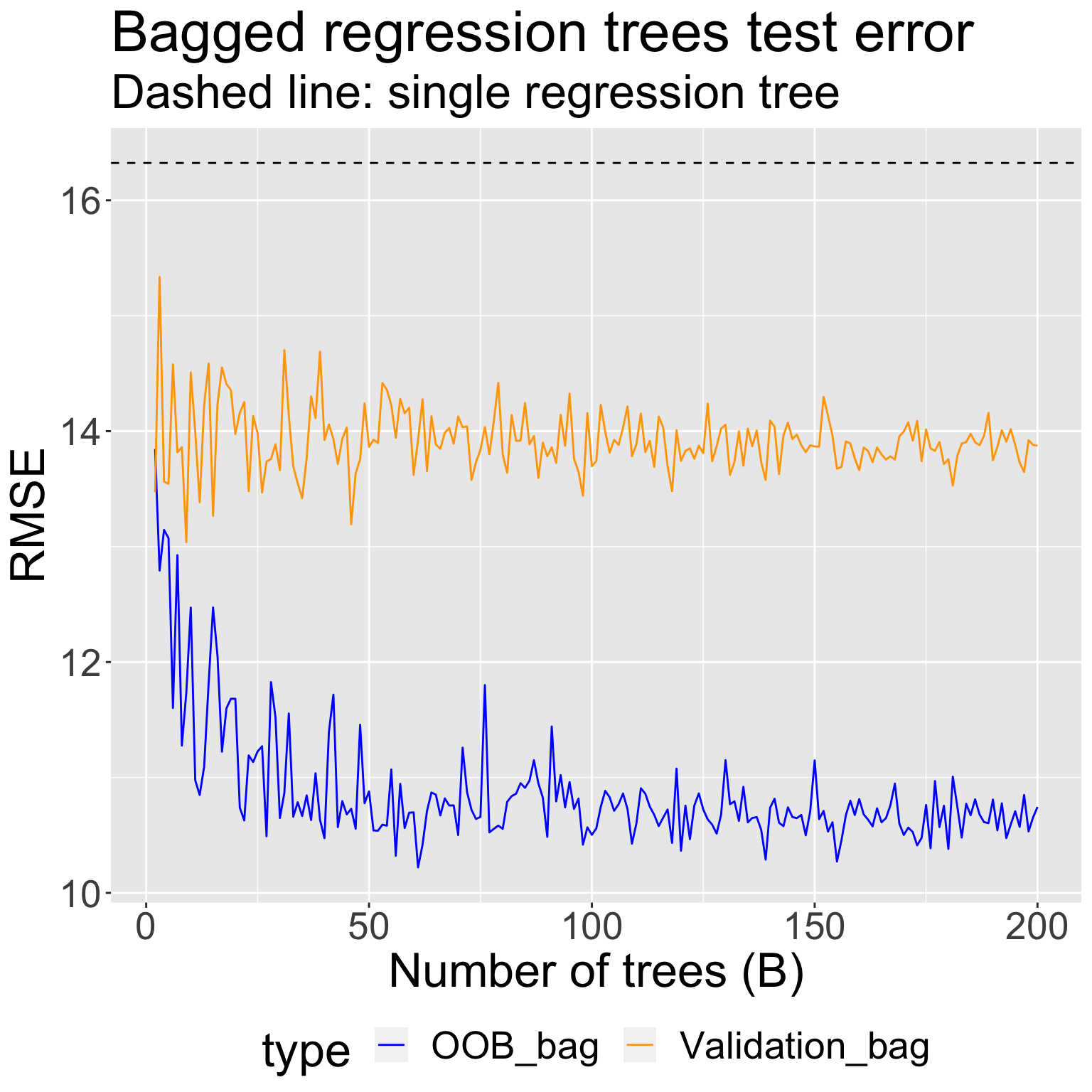
Mite data
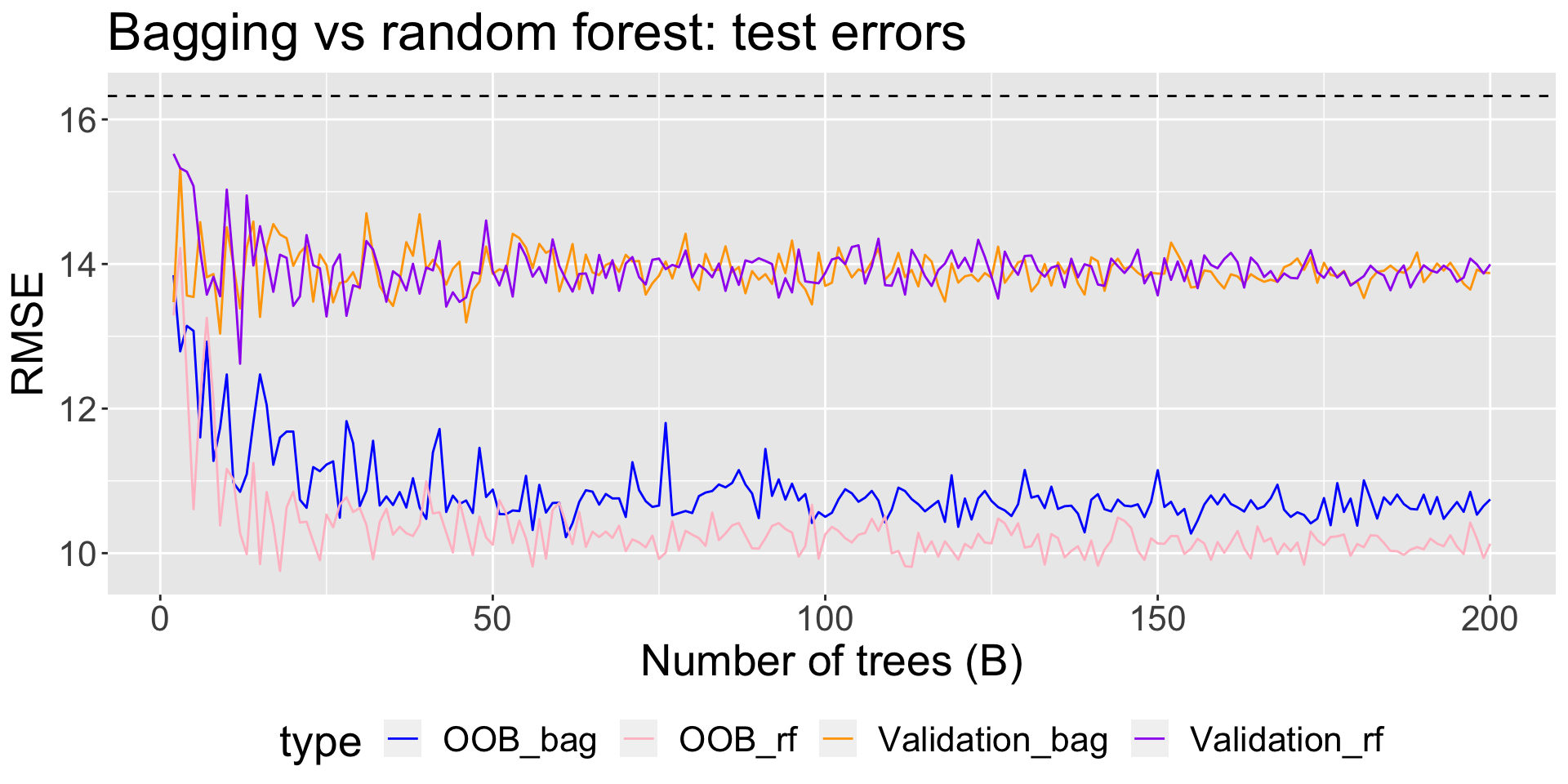
I fit bagged regression trees for \(B = 2, 3, \ldots, 200\) bootstrapped sets using
All the data, and obtained an estimate of test RMSE using the OOB samples
A training set of 2/3 of the original observations, and obtained an estimate of the test RMSE using the held-out validation set
Variable importance measures
Bagging can result in difficulty in interpretation: it’s no longer clear which predictors are most important to the procedure
But one main attraction of decision trees is their interpretability!
Can obtain an overall summary of importance of each predictor using the residual error:
- For bagged regression trees, record the total amount that MSE decreases due to splits over a given predictor, averaged over \(B\) (higher explanatory power \(\rightarrow\) larger decrease in MSE \(\rightarrow\) more important)
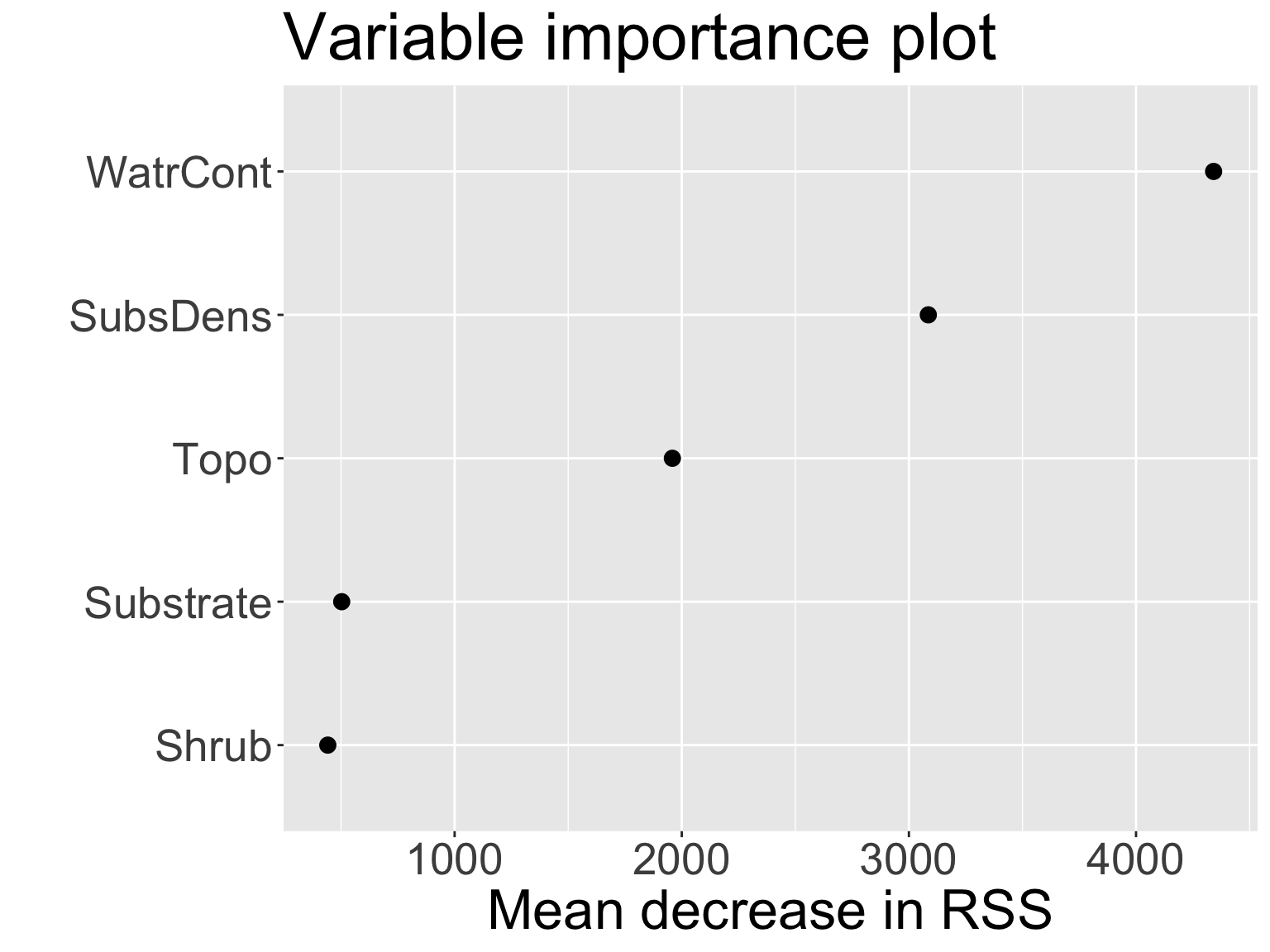
WatrContis the most important variable. This should make sense!Live code!
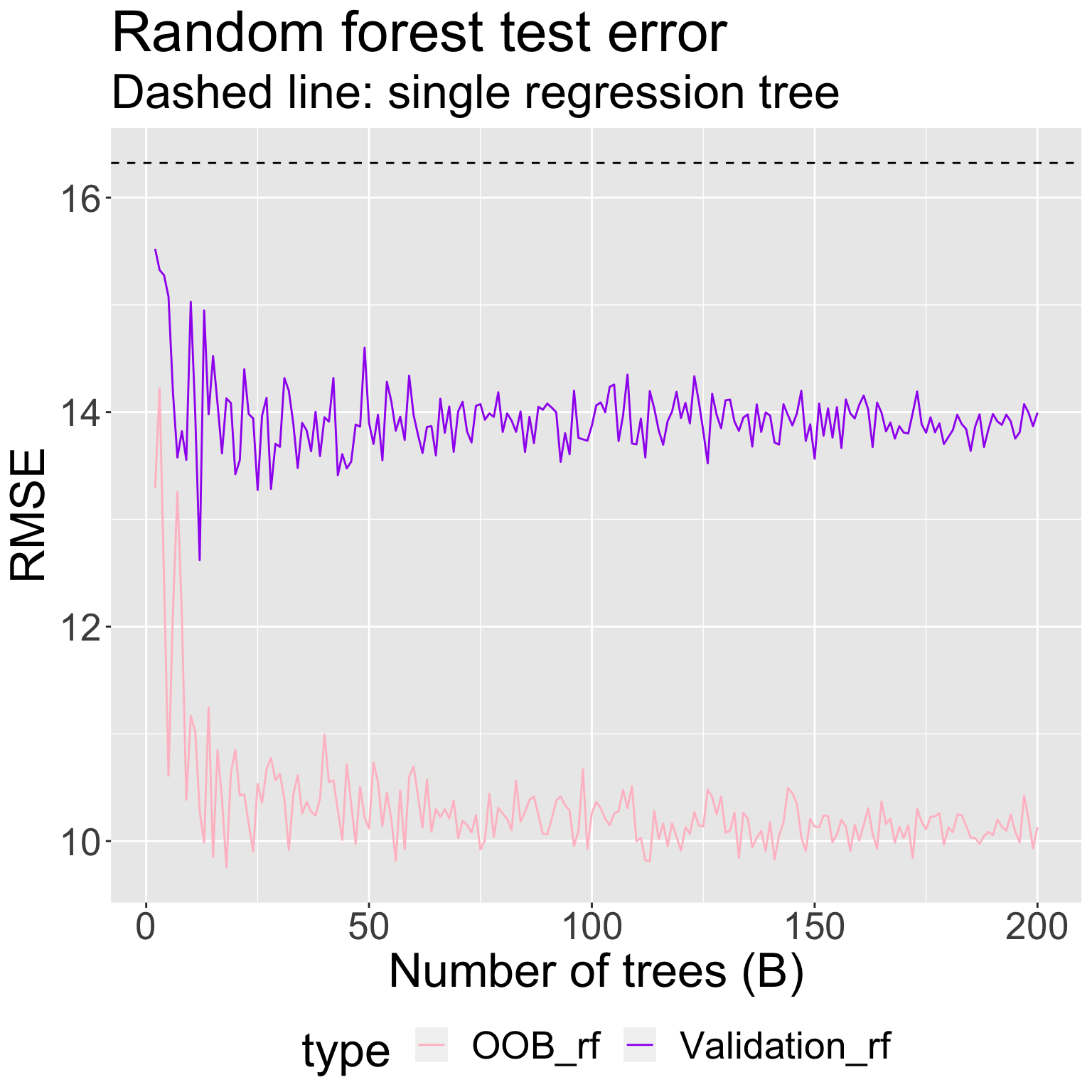
Mite data
For \(B = 2, 3, \ldots, 200\) tree, I fit a random forest with \(m = 2\) candidate predictors at each split using
All the data, and obtained an estimate of test RMSE using the OOB samples
A training set of 2/3 of the original observations (the same as in bagging), and obtained an estimate of the test RMSE using the held-out validation set
Variable importance
- As with bagged regression trees, can obtain variable importance measure of each predictor in random forests using RSS:
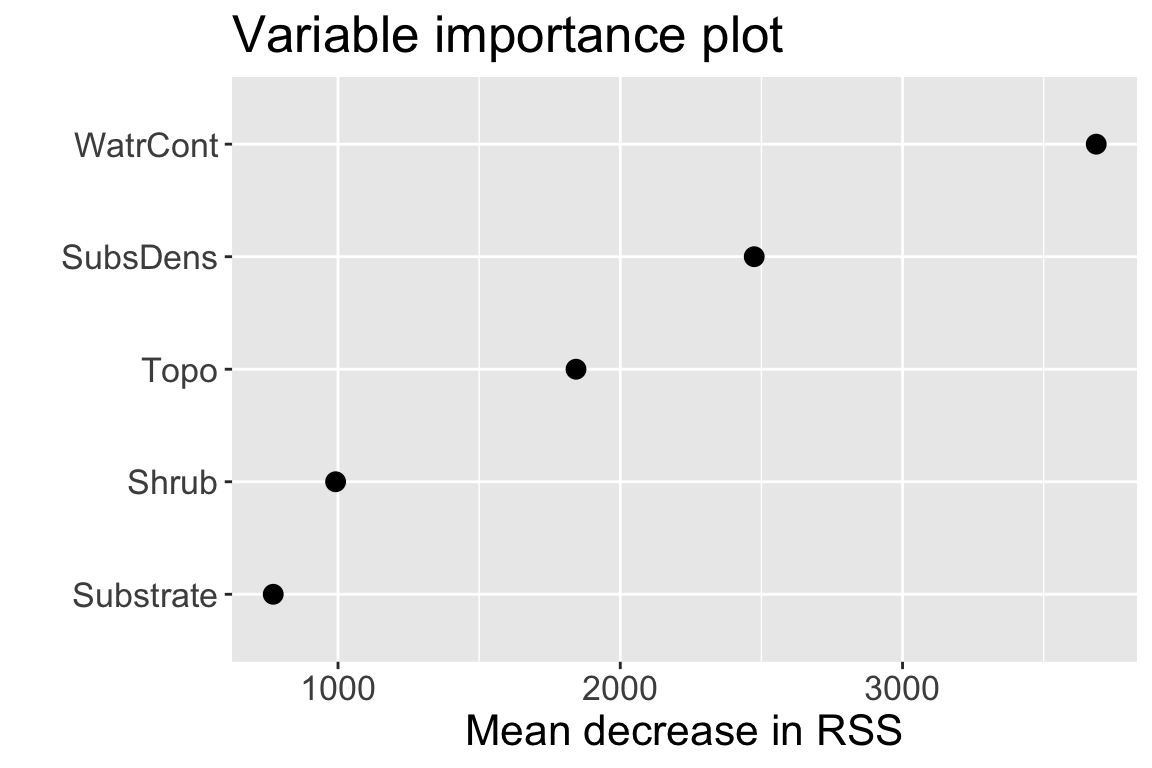
WatrContis still the most important variable
Random forests vs bagging: prediction
Comparing estimated test error when fitting bagged regression trees vs random forests to mite data:
Random forests vs bagging: inference
Comparing variable importance from the two models:
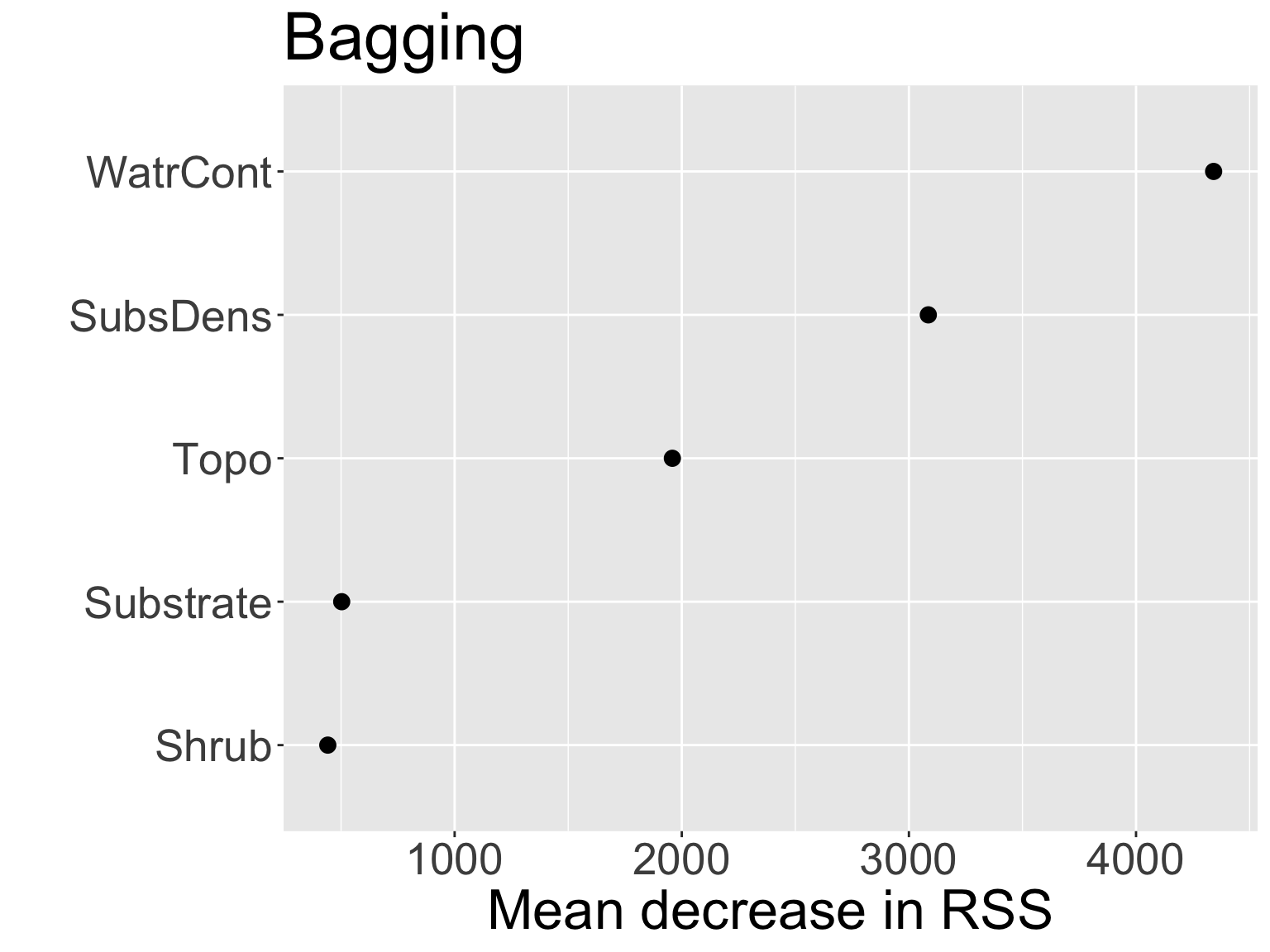
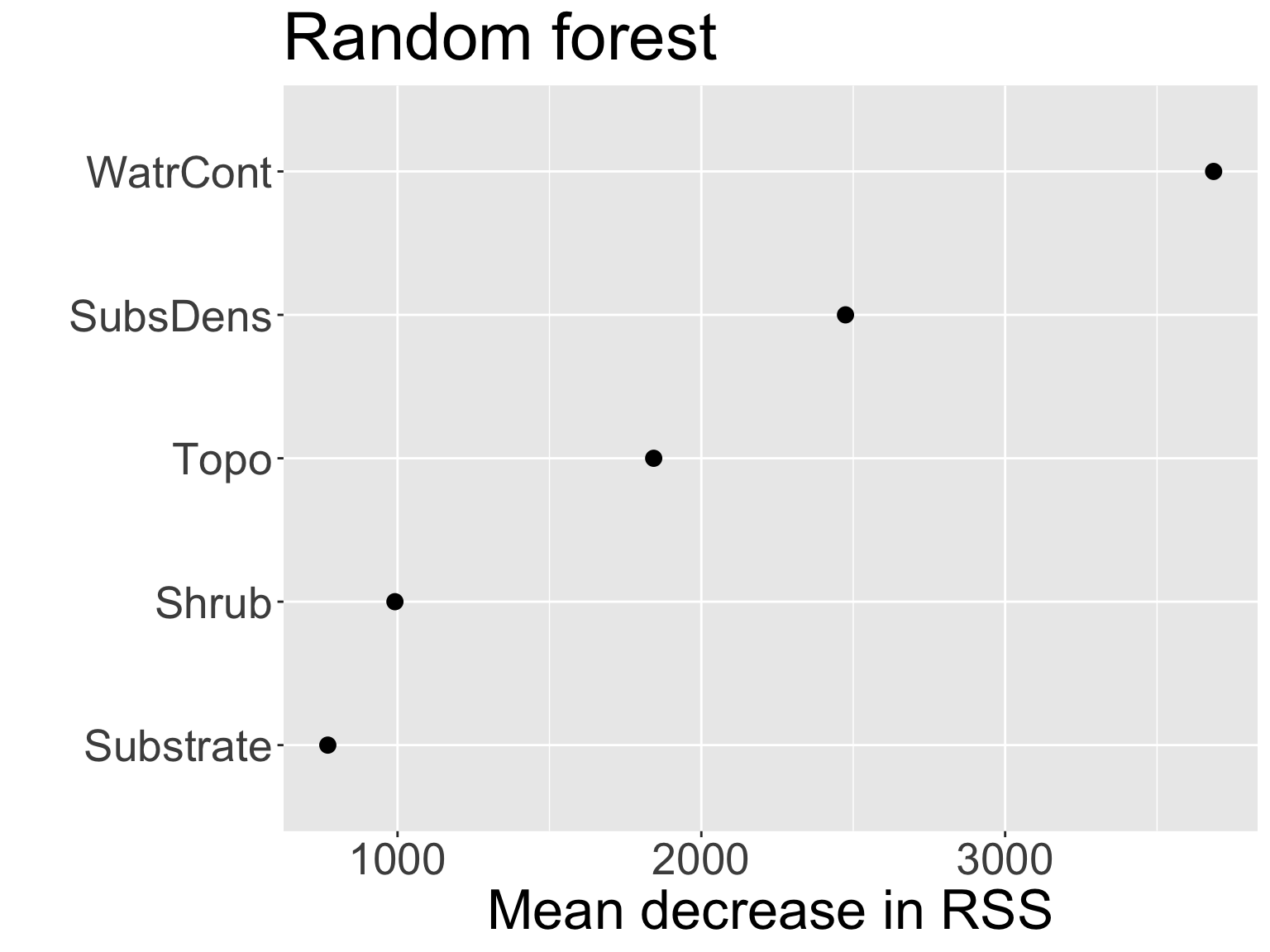
- Notice the swap in order of
ShrubandSubstrate